
Data extraction, which collects or retrieves varied information from diverse sources, is the core part of data science. It is the process of obtaining data from a certain source and transferring it to a new environment. It enables businesses to transfer data from external sources to their own database. This blog will go into detail about data extraction, including its various types, tools, and processes. FITA Academy provides a Data Science Course in Chennai for anyone interested in learning more about Data Extraction and associated tools.
What is Data Extraction?
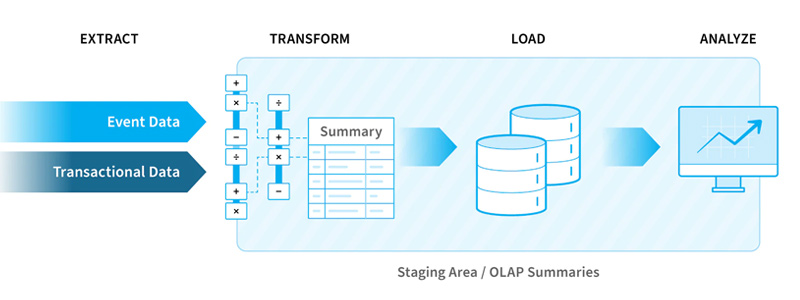
Data extraction holds a vital position in the field of data science. It involves the comprehensive process of gathering and retrieving data from diverse sources, followed by the transformation of this data into a suitable format that is manageable to analysis. As a fundamental step in data science, data extraction is critical for conducting effective data analysis. The key components of data extraction include:
- Data Collection
- Data Integration
- Data Cleaning and Preprocessing
- Feature Engineering
- Data Transformation
- Data Sampling
- Data Security and Privacy
Types of Data Extraction
When extracting data from various sources, Two types of extraction are commonly used:
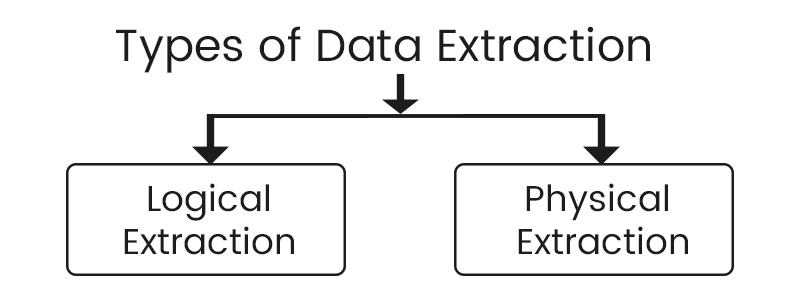
- Logical Extraction: Logical extraction is concerned with obtaining data based on its logical representation rather than directly contacting the physical source. This method entails comprehending the structure, semantics, relationships, properties, and arrangement of the data. Logical extraction often entails querying databases, using APIs, or leveraging data integration technologies to extract structured data.
- Physical Extraction: On the other hand, physical extraction involves direct access to the physical source system and retrieving the data at its raw level. This approach requires interacting with the source system's APIs, file systems, databases, or other data extraction mechanisms to obtain the data in its original, unprocessed form.
Both methods involve crawling (moving) and retrieving data but differ in how the data is collected and processed. To gain practical expertise in data science, consider enrolling in Data Science Courses in Bangalore which offers comprehensive training, utilizing various programming languages like Python, R, SQL, and more, enabling learners to master the intricacies of data science.
Data Extraction and ETL
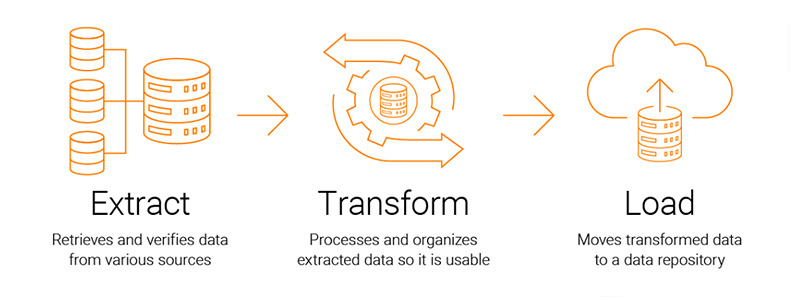
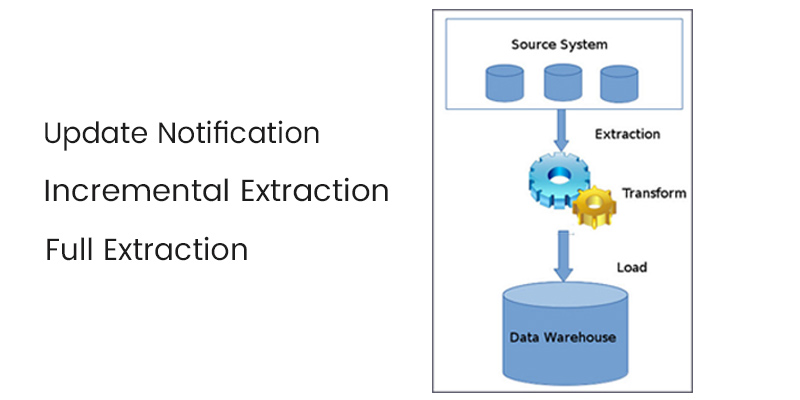
Data extraction involves two processes: ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). These steps are essential for preparing data for business intelligence (BI) or analysis as part of a data integration plan. However, data extraction is only one part of the ETL process. Organizations can aggregate data from numerous sources into a single location using the entire ETL process.
- Extraction collects data from various sources. This involves identifying and locating relevant data and preparing it for subsequent transformation and loading.
- Transformation encompasses sorting and organizing the data. Additionally, cleansing tasks, such as removing missing values, are performed during this step. Depending on the chosen destination, data transformation may include tasks such as structuring JSON, object names, data typing, and aligning time zones to ensure compatibility with the data destination.
- The final step isloading, where the transformed data is delivered to a central repository for immediate or future analysis.
By executing these steps effectively, organizations can streamline the data ingestion process, ensuring that data is efficiently extracted, transformed, and loaded into a central repository for insightful analysis.
Data Extraction Process
The data extraction process plays an important role in obtaining the necessary data for modeling and analysis. Regardless of the data source, whether it's a database, web scraping, Excel spreadsheet, or other formats, the data extraction process involves the following steps:
- Monitor and handle changes in the data structure:It is essential to continuously monitor and handle any changes occurring during the extraction process. This includes detecting new additions or modifications to existing data. Dealing with these changes programmatically ensures a smooth and reliable data extraction process.
- Retrieve target tables and fields: Determine the specific tables and fields that need to be extracted based on the integration's replication scheme. This ensures that only relevant data is extracted from the source.
- Extract the data: Extract the identified data from the source using appropriate techniques and tools.
Once the data is successfully extracted, it needs to be loaded into a destination platform that facilitates business intelligence (BI) reporting. Popular data storage and analysis options include cloud data warehouses such as Microsoft Azure SQL Data Warehouse, Amazon Redshift, Google BigQuery, or Snowflake. The loading process should be tailored to meet the specific requirements of the chosen destination. Data extractor software is utilized to retrieve structured, poorly structured, and unstructured data from various sources for storage or further transformation. Enrolling in the Data Science Course in Salem allows students to get expertise and a full understanding of data science principles. The training curriculum provides detailed assistance, allowing participants to properly comprehend the fundamental concepts of data science.
API-Specific Challenges
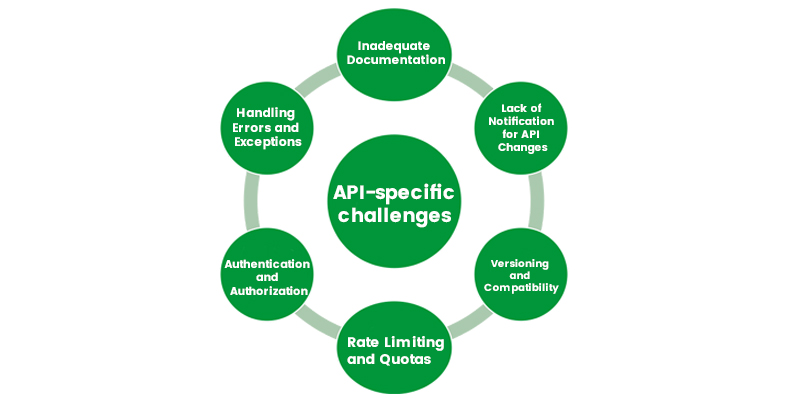
Working with APIs can present several challenges that developers need to be aware of:
- Inadequate Documentation:While some APIs offer extensive and well-organized documentation, many require further information. This might make it difficult for developers to comprehend an API's functionality, response formats, needed arguments, and available endpoints. Complete and well-organized documentation is required for quick development and API integration.
- Lack of Notification for API Changes: APIs evolve as businesses enhance their products or handle problems. However, not all organizations notify their API users in advance of these changes, making it difficult for developers to update their code accordingly.
- Versioning and Compatibility: APIs often introduce new versions, necessitating developers to ensure compatibility between their code and the specific API version they use. Upgrading to a newer API version may require modifications to the codebase, resulting in additional time and effort.
- Rate Limiting and Quotas: Many APIs enforce rate limits or usage quotas to prevent abuse or excessive resource consumption. Developers need to be mindful of these limitations and design their applications accordingly to avoid service disruptions.
- Authentication and Authorization: APIs typically require authentication mechanisms to ensure secure access to data. Implementing the correct authentication mechanisms, such as API keys, tokens, or OAuth, can be challenging and prone to errors if not properly understood.
- Handling Errors and Exceptions: When working with APIs, errors and exceptions can occur at various stages, such as authentication failures, incorrect requests, or network issues. Proper error handling and graceful exception handling are essential to maintain the reliability and stability of the application.
Data Extraction Methods
Data analysts can extract data on demand to meet business needs and analysis goals. There are three primary extraction techniques, ranging from basic to complex:
-
Update notification
The basic method for extracting data from a source system is to have the system issue a notification when a record is changed. Most databases offer automation mechanisms to support database replication, and many SaaS applications provide webhooks that offer similar functionality. It is important to note that change data capture enables real-time or near-real-time data analysis.
-
Incremental extraction
Some data providers are unable to give update notifications. They can, however, detect modified records and offer an extract of those records. The data extraction code must recognize and propagate changes during subsequent ETL (Extract, Transform, Load) processes.
-
Full extraction
When a data source is unable to recognize altered data, a thorough extraction is required for the initial replication. Because there is no way to tell which data has been updated, this requires loading the entire table. However, because to the enormous volume of data that can strain the network, full extraction should be avoided if possible.
When selecting the proper data extraction method, it is essential to evaluate the source system as well as the unique requirements of the study. To understand a what is data source, consider it the location from which the data being used originates. A data source could be the location where physical information is initially digitized. Even the most sophisticated data might become a source if it is accessed by another operation.
Data Extraction Tools
As data sources grow, depending on custom ETL (Extract, Transform, Load) solutions for data extraction becomes inefficient and time-consuming for developers. Maintaining customized scripts becomes difficult when dealing with developing APIs, format changes in sources or destinations, and potential errors that can compromise data quality. Cloud-based ETL tools provide a streamlined approach to data extraction, reducing many maintenance worries. These tools allow users to connect various structured and unstructured data sources to destinations without the need for manual intervention.
Concerns about data extraction and loading challenges are alleviated with cloud-based ETL. Organizations may efficiently extract data from diverse sources and make it available for analytics by employing these powerful data extraction tools. This accessibility helps developers, managers, and particular business units who need data to make informed decisions.
Data Extraction drives Business Intelligence
Effective data extraction is needed to drive business intelligence (BI) and enable successful analytics programs. Understanding the context of data sources and destinations and leveraging the right tools is essential to maximize the value of analytics initiatives. While building a custom data extraction tool is an option for popular data sources, user-friendly ETL tools are available. One of them is Stitch, an open-source solution that simplifies the data replication from diverse sources to desired destinations. By utilizing tools like Stitch, businesses can expedite the data-gathering process for analysis, ensuring it is done faster, easier, and with increased reliability. This allows them to focus on unleashing the full potential of their data analysis and BI programs to drive valuable insights and informed decision-making.
Data extraction is a fundamental data science procedure that enables scientists to acquire and prepare data from multiple sources for study. It enables them to gain relevant insights, make informed decisions, and derive value from today's massive amounts of data. If you are looking for Data Science courses, FITA Academy provides the best Data Science Course in Pondicherry, delivering complete training to improve your skills in this industry.